
本文主要是工作上一些資料用Python程式解決後想做的分享,
但因為檔案資料等不便於網路公開,
所以就用Python先將檔案名稱修改一下,
以便於日後運用與分享。
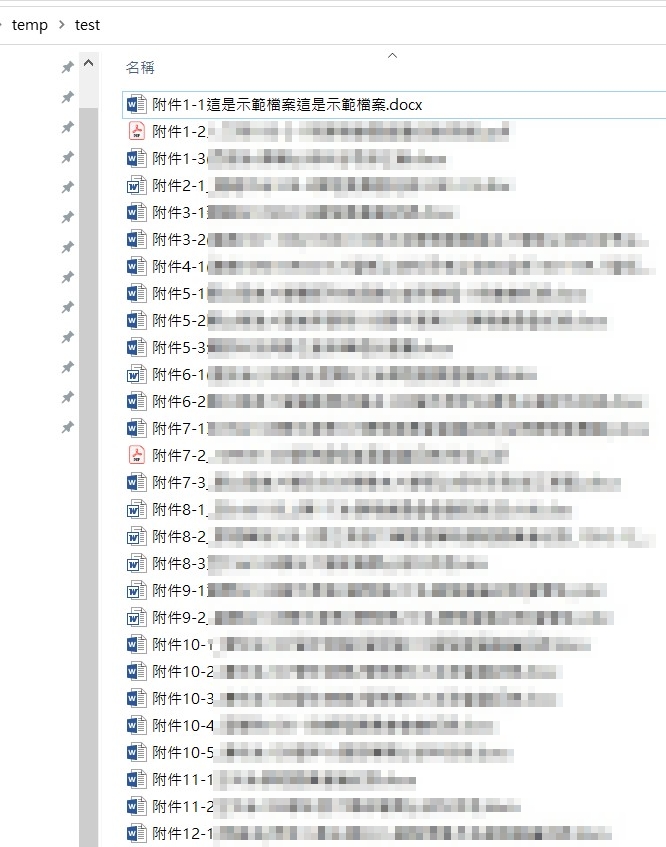
原始資料夾檔案狀況:
以下為程式:
import glob
import os
import re
path = 'd:\\temp\\test\\'
files = glob.glob(path + '*')
print(files)

接下來是用以前分享過的中文姓名自動產生器爬蟲,自動產生中文姓名。
import requests
import pandas as pd
# 設定time為獲取中文姓名100筆的倍數。time=3,就是300筆的意思。
times = 1
cnames = []
for x in range(times):
url = 'http://www.richyli.com/name/index.asp'
r = requests.get(url)
r.encoding = 'big5'
# 將網頁中的資料以分行的方式存成文字檔
result = r.text.splitlines()
# 114是中文姓名開始的列,找到最後一個「、」,設定成為字串的切片位置。
char_index = result[114].rfind("、")
temp = result[114][:char_index]
# 將temp的100筆姓名新增到cnames中
cnames.append(temp)
# 將每100筆姓名的list加一個「、」,再組合成字串存到my_names中
my_names = "、".join(str(x) for x in cnames)
print(my_names)

# 將上面的姓名生成dataframe
df_name = pd.DataFrame(my_names.split('、'), columns=['姓名'])
print(f'中文姓名筆數:{len(df_name)}')
# 將姓名做成list
my_list = df_name.姓名.values.tolist()
print(my_list)

# 將檔名用regex分成三組,第一組為「附件X-X」,第二組為「附件X-X後面的其他檔名」,第三組為「.附檔名」
pattern = '(附件\d+-\d)(.+)(\..+)'
n = 0
for file in files:
file_name = re.findall(pattern, file)
#print(file_name)
# 將檔名前面的附件X-X保留,然後加入"_",再加入中文自動的姓名,再加上附檔名
new_file_name = file_name[0][0] + '_' + my_list[n] + file_name[0][2]
os.rename(file, path + new_file_name)
print(f'{file}已完成')
n += 1
d:\temp\test\附件1-1這是示範檔案這是示範檔案.docx已完成
…
…
以下略。
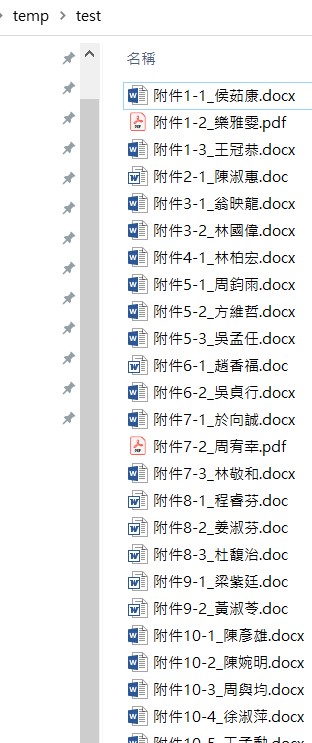
最後輸出結果:
以上即完成本次目標。