來源:讀取「疾病管制署資料開放平台」地區年齡性別統計表-嚴重特殊傳染性肺炎
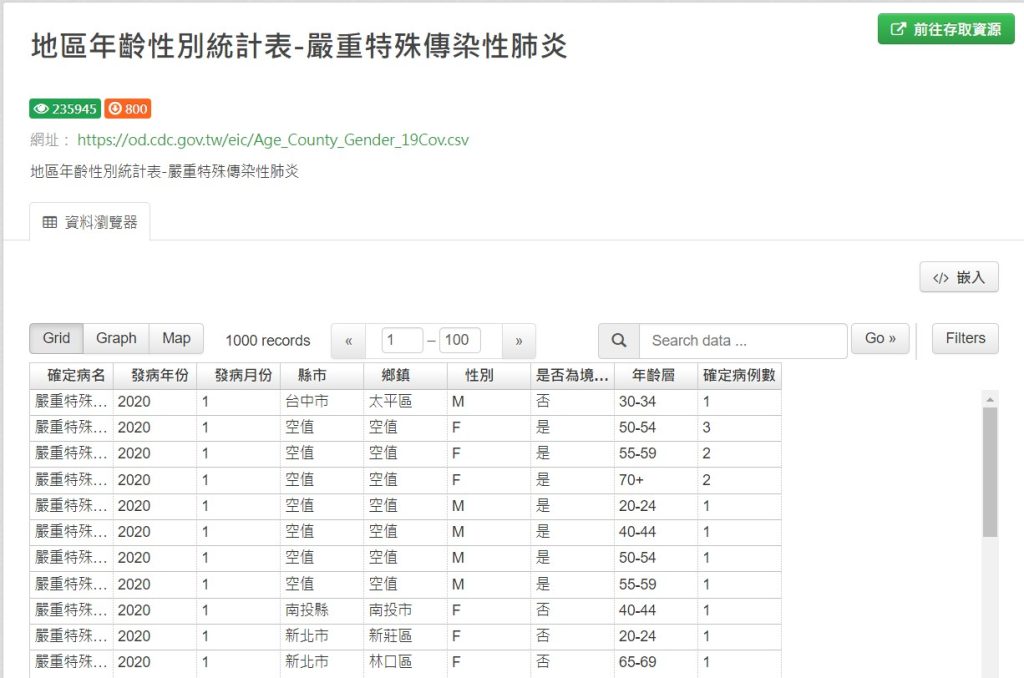
要注意上面「縣市」的欄位有「空值」,「空值」其實是境外移入的個案。
目標:
1. 將各縣市的確定病例數合計後,寫入一個Excel檔案中的各縣市工作表(一檔多工作表)。
2. 將各縣市的確定病例數合計後,寫入以各個縣市命名的各別Excel檔案中(多檔)。
先讀取資料:
import pandas as pd
url = ('https://data.cdc.gov.tw/download?resourceid=95db2a0a-6ea0-4fbc-a87e-521544755db8&dataurl=https://od.cdc.gov.tw/eic/Age_County_Gender_19Cov.csv')
df = pd.read_csv(url)
print(len(df))
print(df.columns)
df.head()
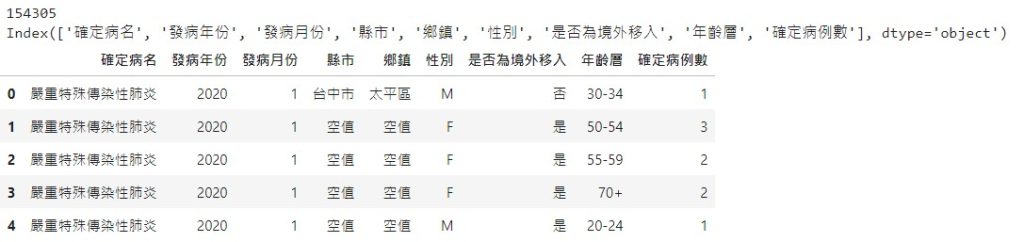
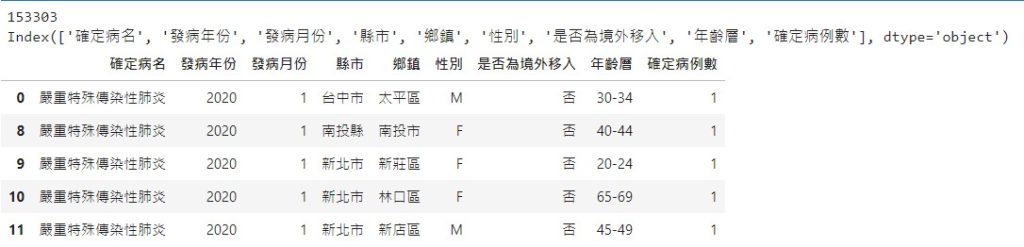
將縣市等於空值的資料列刪除
df = df[~(df['縣市']=='空值')]
print(len(df))
print(df.columns)
df.head()
順便記錄一下如何將字串切割成list(源自stacksoverflow),轉為欄位名稱:
# 第一種方式
exam_string = '國文英語數學自然社會公民'
n = 2
exams = [exam_string[i:i+n] for i in range(0, len(exam_string), n)]
df.columns = exams
目標1:
將各縣市的確定病例數合計後,寫入一個Excel檔案中的各縣市工作表(一檔多工作表)。
# 只拿資料中的「縣市」及「確定病例數」來示範
df = df[['縣市', '確定病例數']].groupby('縣市').sum('確定病例數').reset_index()
with pd.ExcelWriter(
"mytest.xlsx",
mode="w",
engine="openpyxl",
) as writer:
for city in df['縣市']:
sheet = df[df['縣市']==city]
sheet.to_excel(writer, sheet_name=city, index=False)
寫入mytest.xlsx後,呈現的畫面:

目標2:
將各縣市的確定病例數合計後,寫入以各個縣市命名的各別Excel檔案中(多檔)。
# 只拿資料中的「縣市」及「確定病例數」來示範
df = df[['縣市', '確定病例數']].groupby('縣市').sum('確定病例數').reset_index()
for city in df['縣市']:
file = df[df['縣市']==city]
file.to_excel((city + '.xlsx'), index=False)
檔案總管中,可以看到寫入的多個Excel檔案:
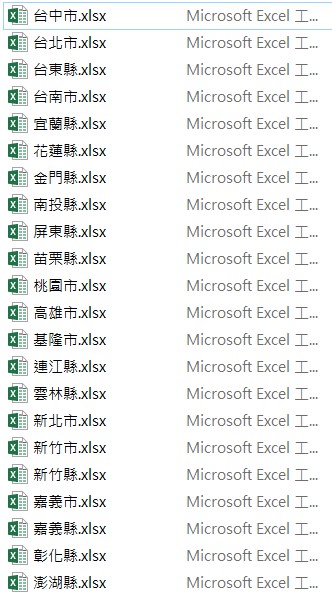
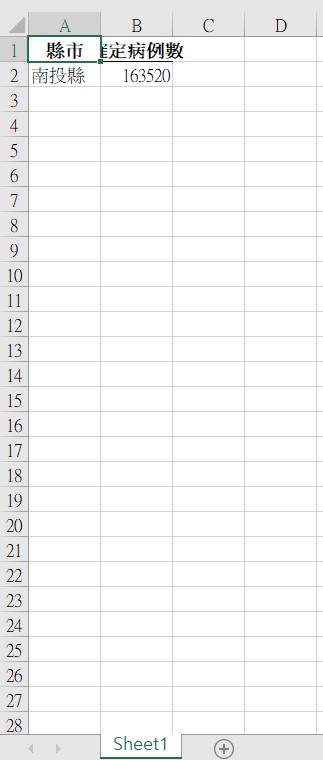
打開其中的「南投縣」檔案: