
本文姓名資料源自於「中文姓名產生器」網站,連結如下:
這個網站提供了很棒的中文姓名自動產生的資料,甚至一次最多能產生出2萬筆中文姓名,
應該都符合大部份的使用者的需求了。
這個網站很特別的是,每次連上去,網頁就會自動產生100筆中文姓名。
只要重新整理一次,就會產生100筆中文姓名,透過這樣的網站特性,
我解析了網頁,寫了一個小程式來依需求產生中文姓名(依100的倍數產生)。
這裏要拜託大家不要用程式去造成網站的負擔!!
以下為程式碼:
import requests
import pandas as pd
# 設定time為獲取中文姓名100筆的倍數。time=3,就是300筆的意思。
times = 2
cnames = []
for x in range(times):
url = 'http://www.richyli.com/name/index.asp'
r = requests.get(url)
r.encoding = 'big5'
# 將網頁中的資料以分行的方式存成文字檔
result = r.text.splitlines()
# 114是中文姓名開始的列,找到最後一個「、」,設定成為字串的切片位置。
char_index = result[114].rfind("、")
temp = result[114][:char_index]
# 將temp的100筆姓名新增到cnames中
cnames.append(temp)
# 將每100筆姓名的list加一個「、」,再組合成字串存到my_names中
my_names = "、".join(str(x) for x in cnames)
print(my_names)
# 將上面的姓名生成dataframe
df_name = pd.DataFrame(my_names.split('、'), columns=['姓名'])
print(f'中文姓名筆數:{len(df_name)}')
df_name

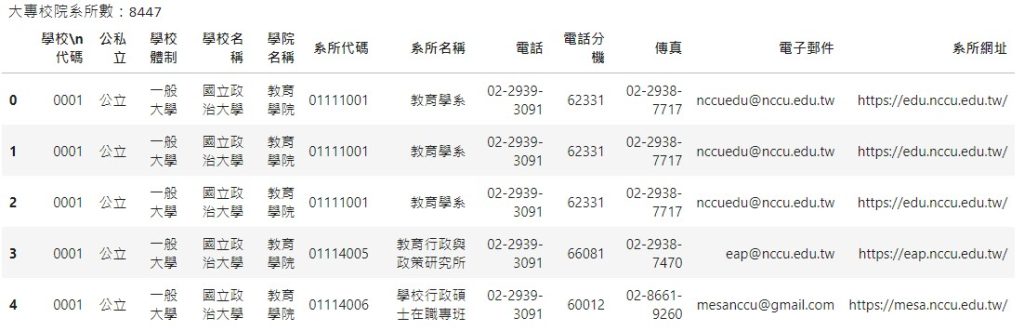
# 讀取111學年度大專校院一覽表- 教育部
url_s = 'https://ulist.moe.gov.tw/Download/StartDownload?FileName=ulistdepartmentlist_college.xlsx'
df_school = pd.read_excel(url_s, skiprows=1)
print(f'大專校院系所數:{len(df_school)}')
df_school.head()
# 隨機抽取10個學校、系所和姓名結合後,做成一個dataframe
df = (pd.concat([df_school[['學校名稱', '系所名稱']]
.sample(n=10).reset_index(drop=True),
df_name.sample(n=10).reset_index(drop=True)], axis=1)
)
df
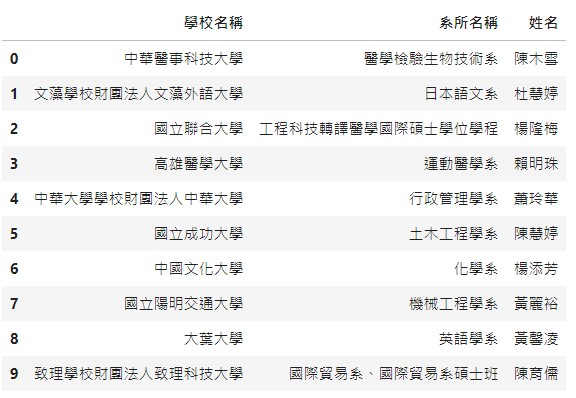
以上就完成10個抽樣學校、系所及姓名的組名!!