
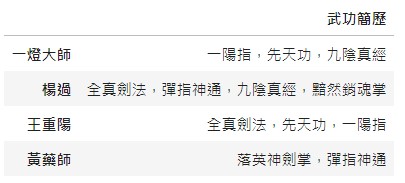
原始資料:
| 武功簡歷 | |
|---|---|
| 一燈大師 | 一陽指,先天功,九陰真經 |
| 楊過 | 全真劍法,彈指神通,九陰真經,黯然銷魂掌 |
| 王重陽 | 全真劍法,先天功,一陽指 |
| 黃藥師 | 落英神劍掌,彈指神通 |
將武功簡歷中有學過的標示為「1」,沒學過的標示為「0」。
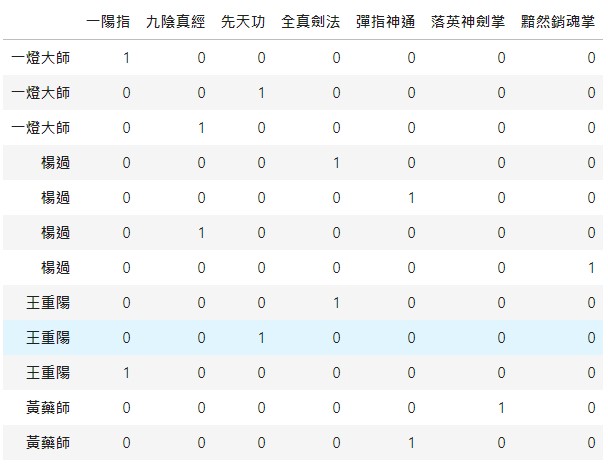
預期結果:
| 武功簡歷 | 一陽指 | 九陰真經 | 先天功 | 全真劍法 | 彈指神通 | 落英神劍掌 | 黯然銷魂掌 | |
|---|---|---|---|---|---|---|---|---|
| 一燈大師 | 一陽指,先天功,九陰真經 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 楊過 | 全真劍法,彈指神通,九陰真經,黯然銷魂掌 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
| 王重陽 | 全真劍法,先天功,一陽指 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 黃藥師 | 落英神劍掌,彈指神通 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
import pandas as pd
df = pd.DataFrame({'武功簡歷': {'楊過': '全真劍法,彈指神通,九陰真經,黯然銷魂掌',
'黃藥師': '落英神劍掌,彈指神通',
'王重陽': '全真劍法,先天功,一陽指',
'一燈大師': '一陽指,先天功,九陰真經'}}
)
df
# pandas explode 配合 pipe 及 get_dummies後的狀況
df['武功簡歷'].str.split(',').explode().pipe(pd.get_dummies)
# 最終程式以人物 groupby 後,對所有的武功做加總得到結果
df.join(df['武功簡歷'].str.split(',').explode().pipe(pd.get_dummies).groupby(level=0).sum())

這樣就完成我們的目標了!!