本文來自於ithelp的發問:
https://ithelp.ithome.com.tw/questions/10206115#_=_
一年多以前自己也試著寫了二種迴圈方式的解答,最近又再想起這個解答。
之前的迴圈程式,請直接參考以上的連結,本文不再重複。
這次試著不用迴圈的方式再寫一次解答。
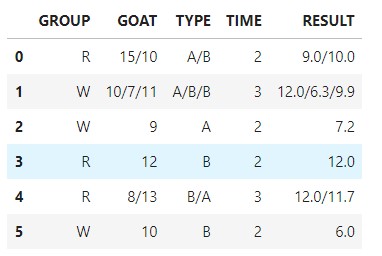
原始資料如下:
| GROUP | GOAT | TYPE | TIME | |
|---|---|---|---|---|
| 0 | R | 15/10 | A/B | 2 |
| 1 | W | 10/7/11 | A/B/B | 3 |
| 2 | W | 9 | A | 2 |
| 3 | R | 12 | B | 2 |
| 4 | R | 8/13 | B/A | 3 |
| 5 | W | 10 | B | 2 |
計算條件如下:
- (GROUP = ‘R’) & (GROUP = ‘A’),RESULT = GOAT * TIME * 0.3
- (GROUP = ‘R’) & (GROUP = ‘B’),RESULT = GOAT * TIME * 0.5
- (GROUP = ‘W’) & (GROUP = ‘A’),RESULT = GOAT * TIME * 0.4
- (GROUP = ‘W’) & (GROUP = ‘B’),RESULT = GOAT * TIME * 0.3
預期最後結果:
| GROUP | GOAT | TYPE | TIME | RESULT | |
|---|---|---|---|---|---|
| 0 | R | 15/10 | A/B | 2 | 9.0/10.0 |
| 1 | W | 10/7/11 | A/B/B | 3 | 12.0/6.3/9.9 |
| 2 | W | 9 | A | 2 | 7.2 |
| 3 | R | 12 | B | 2 | 12.0 |
| 4 | R | 8/13 | B/A | 3 | 12.0/11.7 |
| 5 | W | 10 | B | 2 | 6.0 |
這次改寫的程式如下:
import pandas as pd
import numpy as np
df = pd.DataFrame(
{
'GROUP': ['R','W','W','R','R','W'],
'GOAT': ['15/10','10/7/11','9','12','8/13','10'],
'TYPE': ['A/B','A/B/B','A','B','B/A','B'],
'TIME': [2,3,2,2,3,2]
}
)
df
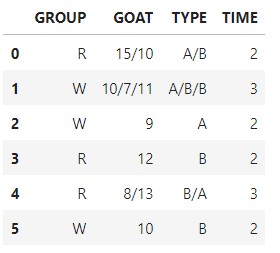
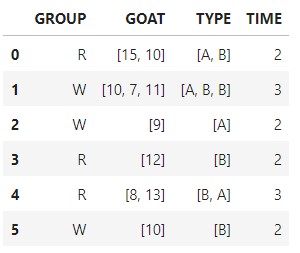
# 先複製一個dfcopy來做運算
dfcopy = df.copy()
dfcopy['GOAT'] = dfcopy['GOAT'].str.split('/')
dfcopy['TYPE'] = dfcopy['TYPE'].str.split('/')
dfcopy
# 確認一下欄位值的類型
dfcopy.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 10 entries, 0 to 9
Data columns (total 5 columns):
Column Non-Null Count Dtype
0 index 10 non-null int64
1 GROUP 10 non-null object
2 GOAT 10 non-null object
3 TYPE 10 non-null object
4 TIME 10 non-null int64
dtypes: int64(2), object(3)
memory usage: 528.0+ bytes
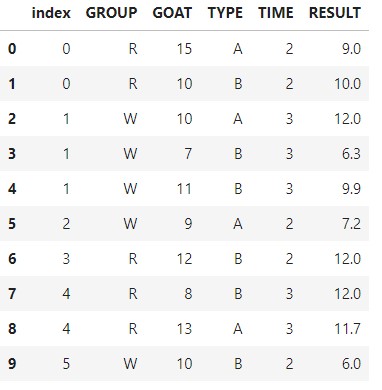
接下來開始故運算:
dfcopy.loc[(dfcopy['GROUP'] == 'R') & (dfcopy['TYPE'] == 'A'), 'RESULT'] = dfcopy['GOAT'].astype(int) * dfcopy['TIME'] * 0.3
dfcopy.loc[(dfcopy['GROUP'] == 'R') & (dfcopy['TYPE'] == 'B'), 'RESULT'] = dfcopy['GOAT'].astype(int) * dfcopy['TIME'] * 0.5
dfcopy.loc[(dfcopy['GROUP'] == 'W') & (dfcopy['TYPE'] == 'A'), 'RESULT'] = dfcopy['GOAT'].astype(int) * dfcopy['TIME'] * 0.4
dfcopy.loc[(dfcopy['GROUP'] == 'W') & (dfcopy['TYPE'] == 'B'), 'RESULT'] = dfcopy['GOAT'].astype(int) * dfcopy['TIME'] * 0.3
dfcopy
dfcopy['RESULT'] = dfcopy['RESULT'].replace('', np.nan)
# 將explode後的資料還原成同一個index
df['RESULT'] = (dfcopy.groupby('index', as_index=True)
.agg({'RESULT': lambda x: x.dropna().tolist()})
)
df['RESULT']
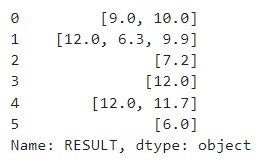
# 將list轉換成string
df['RESULT'] = ['/'.join(map(str, l)) for l in df['RESULT']]
df