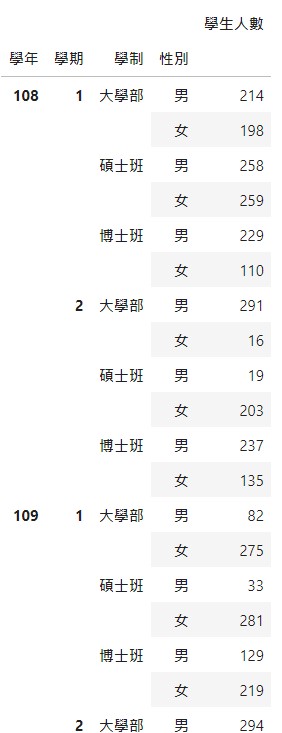
範例資料如下:
學年:108, 109
學期:1, 2
學制:”博士班”, “碩士班”, “大學部”
性別:”女”, “男”
import pandas as pd
import numpy as np
year = [108, 109]
semester = [1, 2]
academic = ['博士班', '碩士班', '大學部']
gender = ['女', '男']
index = pd.MultiIndex.from_product([year, semester, academic, gender],
names=['學年', '學期', '學制', '性別'])
df = pd.DataFrame(np.random.randint(300,size=(24,1)),index=index,columns=["學生人數"])
df
輸出結果太長,只截圖一部份:
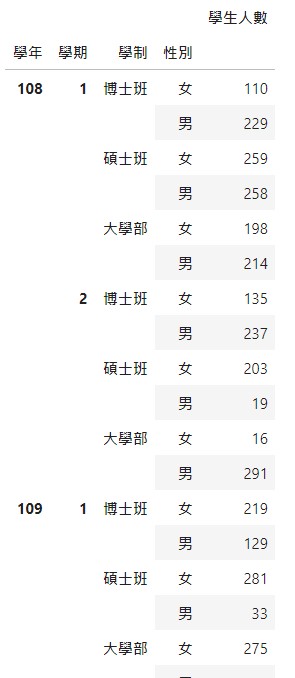
多接下來先把多重索引取消後,複製成dfcopy
dfcopy = df.reset_index()
dfcopy
輸出結果太長,只截圖一部份:
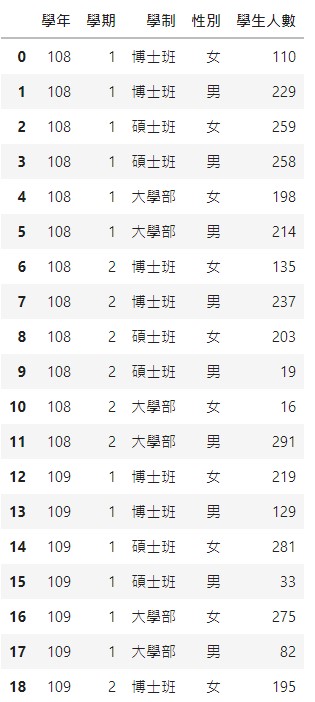
pandas是有一個排序的函數sort_values,但排序的值只能選由小到大,或由大到小。
假設我們希望資料的排序值如下:
學年:108, 109
學期:1, 2
學制:”大學部”, “碩士班”, “博士班”
性別:”男”, “女”
先來看一下sort_values的排序方式:
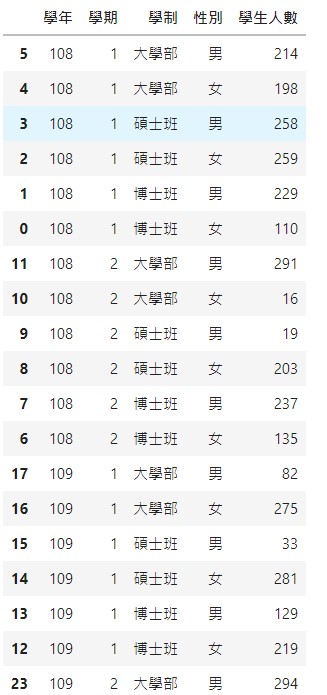
dfcopy.sort_values(['學年', '學期', '學制', '性別'], ascending=[True, True, True, False])
輸出結果太長,只截圖一部份:
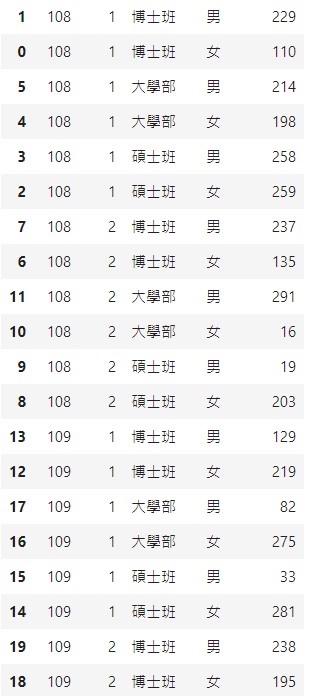
排序的結果,學年、學期、性別這三個欄位的值都剛好能用內定的排序排好順序,
但偏偏學制的排序不如預期。
學制由小到大的排序:”博士班”, “大學部”, “碩士班”
學制由大到小的排序:”碩士班”, “大學部”, “博士班”
但我們要的排序是這樣:”大學部”, “碩士班”, “博士班”
以此範例而言,
我們很確定學年、學期都是數字,可以很容易控制排序。
假設學制、性別我們要自訂排序,
我們就把這2個欄位先轉成類別後,依自訂需求排序:
dfcopy['學制'] = pd.Categorical(dfcopy['學制'], ["大學部", "碩士班", "博士班"])
dfcopy['性別'] = pd.Categorical(dfcopy['性別'], ["男", "女"])
dfcopy.sort_values(['學年', '學期', '學制', '性別'])
輸出結果太長,只截圖一部份:
dfcopy = dfcopy.sort_values(['學年', '學期', '學制', '性別']).reset_index(drop=True)
dfcopy
輸出結果太長,只截圖一部份:
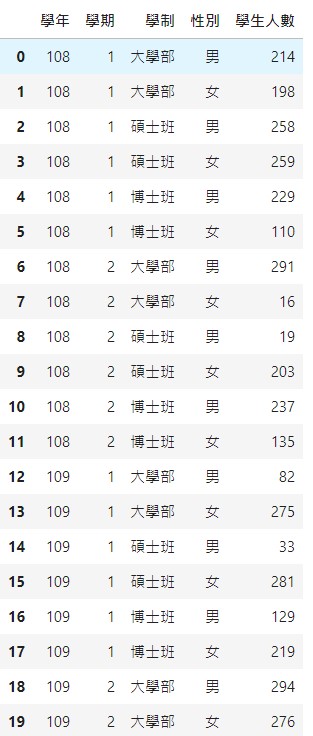
最後的結果,可以再還原成MultiIndex。
dfcopy = dfcopy.set_index(['學年', '學期', '學制', '性別'])
dfcopy
輸出結果太長,只截圖一部份: