本文來自於ithelp網友之發問,網址如下:
https://ithelp.ithome.com.tw/questions/10212370
因上面問答資料有點多,網友又有後續提問,寫成文章比較容易編輯。
原先問題及提問分類成2題:
第1題
test.txt資料檔內容如下:
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
人 4 6 8 “Post
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
####Flow-Volume-Curve####
Pred Pre %... Post %... Chg...
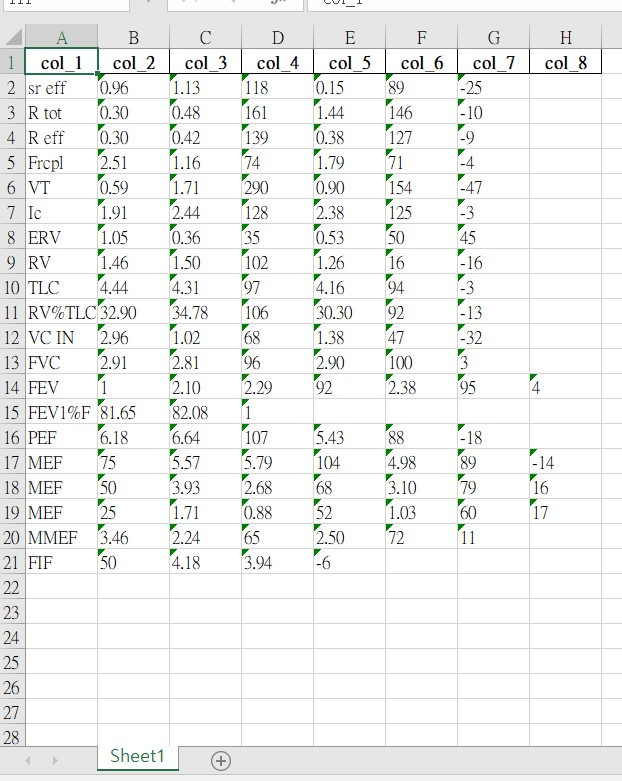
sr eff 0.96 1.13 118 0.15 89 -25
R tot 0.30 0.48 161 1.44 146 -10
R eff 0.30 0.42 139 0.38 127 -9
Frcpl 2.51 1.16 74 1.79 71 -4
VT 0.59 1.71 290 0.90 154 -47
Ic 1.91 2.44 128 2.38 125 -3
ERV 1.05 0.36 35 0.53 50 45
RV 1.46 1.50 102 1.26 16 -16
TLC 4.44 4.31 97 4.16 94 -3
RV%TLC 32.90 34.78 106 30.30 92 -13
VC IN 2.96 1.02 68 1.38 47 -32
FVC 2.91 2.81 96 2.90 100 3
FEV 1 2.10 2.29 92 2.38 95 4
FEV1%F 81.65 82.08 1
PEF 6.18 6.64 107 5.43 88 -18
MEF 75 5.57 5.79 104 4.98 89 -14
MEF 50 3.93 2.68 68 3.10 79 16
MEF 25 1.71 0.88 52 1.03 60 17
MMEF 3.46 2.24 65 2.50 72 11
FIF 50 4.18 3.94 -6
Substance ventolin
目標:讀取「Pred Pre %… Post %… Chg…」與「Substance ventolin」之間的內容,整理成以下格式:
code1:
# 先找出讀取檔案的起始和結束行
import pandas as pd
import re
file = 'test.txt'
# 設定空的索引
indexes = []
with open(file) as f:
lines = f.readlines()
for i, line in enumerate(lines):
# 搜尋檔案要讀取的起始位置
if line.startswith('Pred Pre %... Post %... Chg...'):
# 找到起始位置後,下一行才開始讀取
s = i+1
# 搜尋檔案要讀取的結束位置
elif line.startswith('Substance ventolin'):
e = i
indexes.append((s, e))
else:
pass
# 設定空的list儲存要整理的英文名字
result_name = []
# 設定空的list儲存要整理的數據
result_data = []
# 讀取起始和結束位置中間的資料
for line in lines[s:e]:
# 這邊是用ccutmis前輩的Regex來尋找與切割資料:
temp = re.findall('(^[A-Za-z%]+.*[A-Za-z%].)(.*)$', line)
# 原始資料中的英文名存到result_name
result_name.append(temp[0][0])
# 原始資料中的數據存到result_name
result_data.append(temp[0][1].split(' '))
df_name = pd.DataFrame(result_name)
df_data = pd.DataFrame(result_data)
# 將以上的2個dataframe 串接
df = pd.concat([df_name, df_data], axis=1)
# 將欄名修正為「col_1......, col_x」
df.columns=['col_' + str(x) for x in range(1, len(df.columns)+1)]
df
結果如下:
第2題
假設有3個text檔案,資料分別如下:
test1.txt:
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
人 4 6 8 “Post
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
####Flow-Volume-Curve####
Pred Pre %... Post %... Chg...
sr eff 0.96 1.13 118 0.15 89 -25
R tot 0.30 0.48 161 1.44 146 -10
R eff 0.30 0.42 139 0.38 127 -9
Frcpl 2.51 1.16 74 1.79 71 -4
VT 0.59 1.71 290 0.90 154 -47
Substance ventolin
test2.txt:
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
人 4 6 8 “Post
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
####Flow-Volume-Curve####
Pred Pre %... Post %... Chg...
Ic 1.91 2.44 128 2.38 125 -3
ERV 1.05 0.36 35 0.53 50 45
RV 1.46 1.50 102 1.26 16 -16
TLC 4.44 4.31 97 4.16 94 -3
RV%TLC 32.90 34.78 106 30.30 92 -13
VC IN 2.96 1.02 68 1.38 47 -32
FVC 2.91 2.81 96 2.90 100 3
Substance ventolin
test3.txt:
3 i
2 10-
2 ,,
1 / 1 cia
0 \ 0 0 By Pte
人 4 6 8 “Post
-1 / “I 5-
2
2 / TO
-3
4g / 人 ]
Volume shift [ml] 15-
####Flow-Volume-Curve####
Pred Pre %... Post %... Chg...
FEV 1 2.10 2.29 92 2.38 95 4
FEV1%F 81.65 82.08 1
PEF 6.18 6.64 107 5.43 88 -18
MEF 75 5.57 5.79 104 4.98 89 -14
MEF 50 3.93 2.68 68 3.10 79 16
MEF 25 1.71 0.88 52 1.03 60 17
MMEF 3.46 2.24 65 2.50 72 11
FIF 50 4.18 3.94 -6
Substance ventolin
目標2-1:批次讀取text檔案,處理完後,輸出成一個test.xlsx檔案,分成「test1, test2, test3」三個工作表。
目標2-2:批次讀取text檔案,處理完後結合所有資料,輸出成一個test.xlsx檔案。
code 2-0:
import glob
import re
import pandas as pd
# 假設所有的text檔案放在20230329_test的目錄下
files = glob.glob('./20230329_test/*.txt')
# 先印出所有的檔案
files
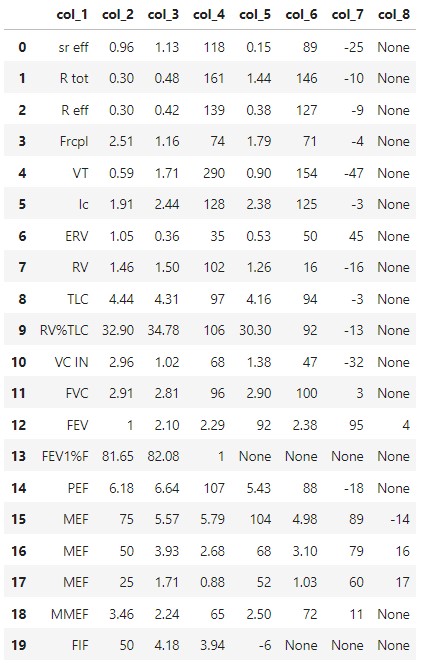
結果如下:
[‘./20230329_test\test1.txt’,
‘./20230329_test\test2.txt’,
‘./20230329_test\test3.txt’]
code 2-1:
# 設定空的list儲存迴圈的所有dataframe
df_list = []
# 設定空的list儲存dataframe的工作表名稱
sheet_list = []
# 迴圈讀取所有要處理的檔案
for file in files:
# 將txt的檔案名稱不含副檔名存入sheet_name
sheet_list.append(file[-9:-4])
# 先找出讀取檔案的起始和結束行
with open(file) as f:
s, e = None, None
lines = f.readlines()
for i, line in enumerate(lines):
# 搜尋檔案要讀取的起始位置
if line.startswith('Pred Pre %... Post %... Chg...'):
# 找到起始位置後,下一行才開始讀取
s = i+1
# 搜尋檔案要讀取的結束位置
elif line.startswith('Substance ventolin'):
e = i
else:
pass
# 設定空的list儲存要整理的英文名字
result_name = []
# 設定空的list儲存要整理的數據
result_data = []
# 讀取起始和結束位置中間的資料
for line in lines[s:e]:
# 這邊是用ccutmis前輩的Regex來尋找與切割資料:
temp = re.findall('(^[A-Za-z%]+.*[A-Za-z%].)(.*)$', line)
# 原始資料中的英文名存到result_name
result_name.append(temp[0][0])
# 原始資料中的數據存到result_name
result_data.append(temp[0][1].split(' '))
df_name = pd.DataFrame(result_name)
df_data = pd.DataFrame(result_data)
# 將以上的2個dataframe 串接
df = pd.concat([df_name, df_data], axis=1)
# 將欄名修正為「col_1......, col_x」
df.columns=['col_' + str(x) for x in range(1, len(df.columns)+1)]
# 將dataframe存入df_list
df_list.append(df)
# 將上面處理完的資料分成3個工作表,存入原先資料存中的test.xlsx
w = pd.ExcelWriter('./20230329_test/test.xlsx')
for a, b in zip(sheet_list, df_list):
b.to_excel(w, sheet_name=f'{a}', index=False)
w.close()
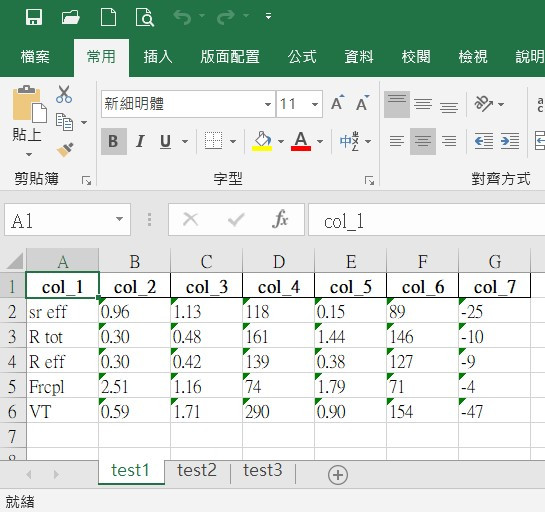
結果如下:
test1工作表
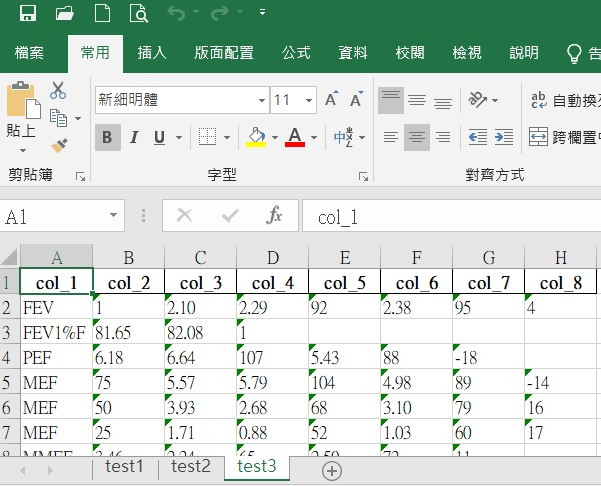
注意test3工作表是col_1-col_8
code 2-2:
# 設定空的list儲存迴圈的所有dataframe
df_list = []
# 設定空的list儲存dataframe的工作表名稱,這個用不到了!!
#sheet_list = []
# 迴圈讀取所有要處理的檔案
for file in files:
# 將txt的檔案名稱不含副檔名存入sheet_name,這個用不到了!!
#sheet_list.append(file[-9:-4])
# 先找出讀取檔案的起始和結束行
with open(file) as f:
s, e = None, None
lines = f.readlines()
for i, line in enumerate(lines):
# 搜尋檔案要讀取的起始位置
if line.startswith('Pred Pre %... Post %... Chg...'):
# 找到起始位置後,下一行才開始讀取
s = i+1
# 搜尋檔案要讀取的結束位置
elif line.startswith('Substance ventolin'):
e = i
else:
pass
# 設定空的list儲存要整理的英文名字
result_name = []
# 設定空的list儲存要整理的數據
result_data = []
# 讀取起始和結束位置中間的資料
for line in lines[s:e]:
# 這邊是用ccutmis前輩的Regex來尋找與切割資料:
temp = re.findall('(^[A-Za-z%]+.*[A-Za-z%].)(.*)$', line)
# 原始資料中的英文名存到result_name
result_name.append(temp[0][0])
# 原始資料中的數據存到result_name
result_data.append(temp[0][1].split(' '))
df_name = pd.DataFrame(result_name)
df_data = pd.DataFrame(result_data)
# 將以上的2個dataframe 串接
df = pd.concat([df_name, df_data], axis=1)
# 將欄名修正為「col_1......, col_x」
df.columns=['col_' + str(x) for x in range(1, len(df.columns)+1)]
# 將dataframe存入df_list
df_list.append(df)
# 將3個檔案串接
df_all = pd.concat(df_list, axis=0).reset_index(drop=True)
# 串接後的檔案存入原先資料存中的test.xlsx
df_all.to_excel('./20230329_test/test.xlsx', index=False)
結果如下: