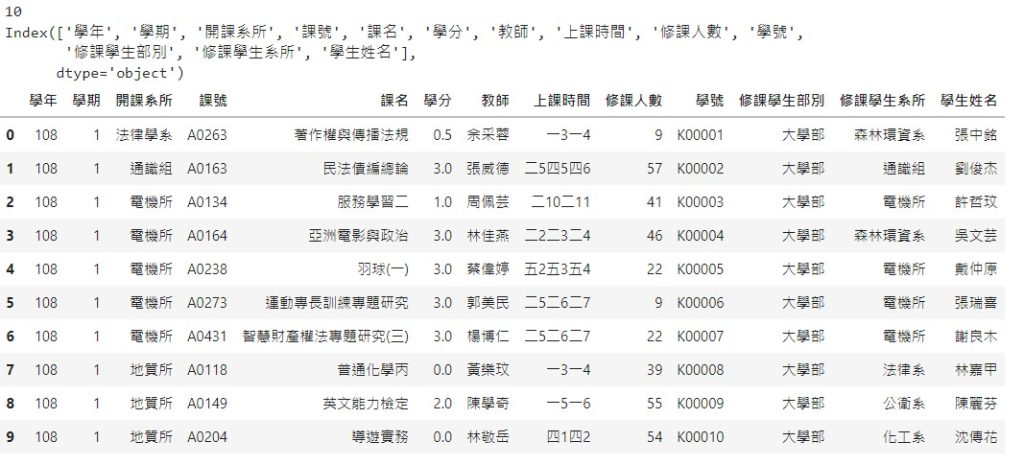
import pandas as pd
dict = {'學年': {0: 108,
1: 108,
2: 108,
3: 108,
4: 108,
5: 108,
6: 108,
7: 108,
8: 108,
9: 108},
'學期': {0: 1, 1: 1, 2: 1, 3: 1, 4: 1, 5: 1, 6: 1, 7: 1, 8: 1, 9: 1},
'開課系所': {0: '法律學系',
1: '通識組',
2: '電機所',
3: '電機所',
4: '電機所',
5: '電機所',
6: '電機所',
7: '地質所',
8: '地質所',
9: '地質所'},
'課號': {0: 'A0263',
1: 'A0163',
2: 'A0134',
3: 'A0164',
4: 'A0238',
5: 'A0273',
6: 'A0431',
7: 'A0118',
8: 'A0149',
9: 'A0204'},
'課名': {0: '著作權與傳播法規',
1: '民法債編總論',
2: '服務學習二',
3: '亞洲電影與政治',
4: '羽球(一)',
5: '運動專長訓練專題研究',
6: '智慧財產權法專題研究(三)',
7: '普通化學丙',
8: '英文能力檢定',
9: '導遊實務'},
'學分': {0: 0.5,
1: 3.0,
2: 1.0,
3: 3.0,
4: 3.0,
5: 3.0,
6: 3.0,
7: 0.0,
8: 2.0,
9: 0.0},
'教師': {0: '余采蓉',
1: '張威德',
2: '周佩芸',
3: '林佳燕',
4: '蔡偉婷',
5: '郭美民',
6: '楊博仁',
7: '黃樂玟',
8: '陳學奇',
9: '林敬岳'},
'上課時間': {0: '一3一4',
1: '二5四5四6',
2: '二10二11',
3: '二2二3二4',
4: '五2五3五4',
5: '二5二6二7',
6: '二5二6二7',
7: '一3一4',
8: '一5一6',
9: '四1四2'},
'修課人數': {0: 9, 1: 57, 2: 41, 3: 46, 4: 22, 5: 9, 6: 22, 7: 39, 8: 55, 9: 54},
'學號': {0: 'K00001',
1: 'K00002',
2: 'K00003',
3: 'K00004',
4: 'K00005',
5: 'K00006',
6: 'K00007',
7: 'K00008',
8: 'K00009',
9: 'K00010'},
'修課學生部別': {0: '大學部',
1: '大學部',
2: '大學部',
3: '大學部',
4: '大學部',
5: '大學部',
6: '大學部',
7: '大學部',
8: '大學部',
9: '大學部'},
'修課學生系所': {0: '森林環資系',
1: '通識組',
2: '電機所',
3: '森林環資系',
4: '電機所',
5: '電機所',
6: '電機所',
7: '法律系',
8: '公衛系',
9: '化工系'},
'學生姓名': {0: '張中銘',
1: '劉俊杰',
2: '許哲玟',
3: '吳文芸',
4: '戴仲原',
5: '張瑞喜',
6: '謝良木',
7: '林嘉甲',
8: '陳麗芬',
9: '沈傳花'}}
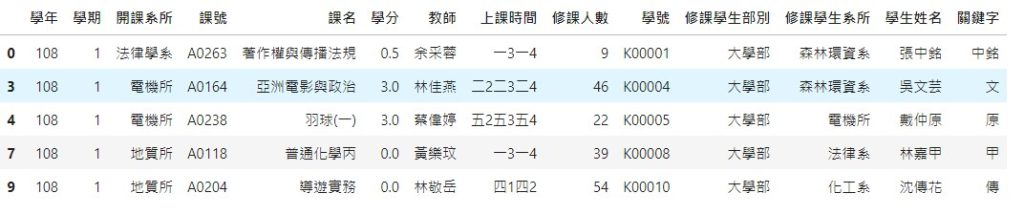
# 設假要篩選學生姓名中含有以下關鍵字的資料
pattern = ['銘', '傳', '淡', '江', '逢', '甲', '中', '原', '文', '化']
df = pd.DataFrame(dict)
print(len(df))
print(df.columns)
df