資料檔:
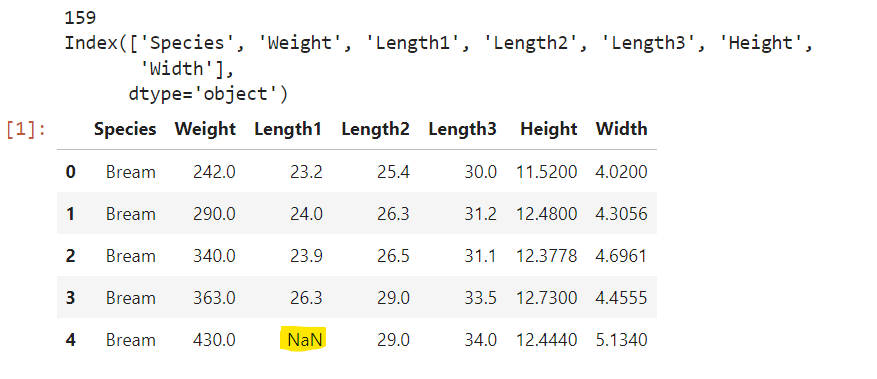
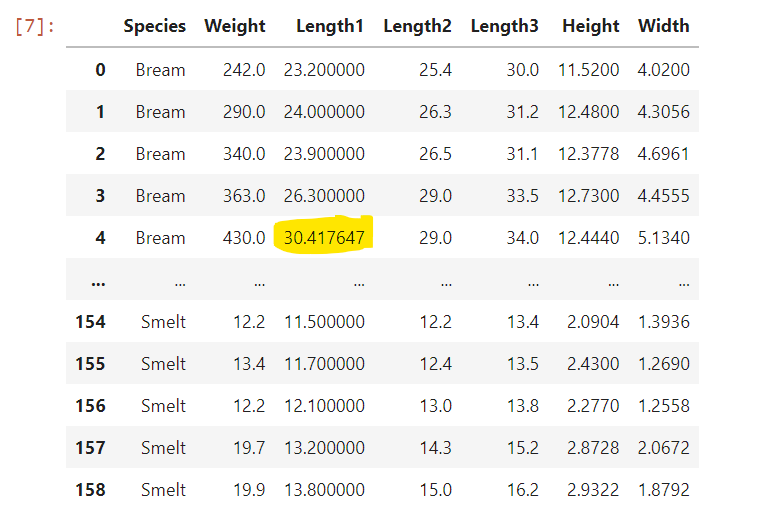
目標:將NaN以平均值填入
import pandas as pd
159
Index(['Species', 'Weight', 'Length1', 'Length2', 'Length3', 'Height',
'Width'],
dtype='object')
| Species | Weight | Length1 | Length2 | Length3 | Height | Width | |
|---|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 23.2 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 24.0 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 23.9 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 26.3 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | NaN | 29.0 | 34.0 | 12.4440 | 5.1340 |
| Length1 | |
|---|---|
| Species | |
| Bream | 30.417647 |
| Parkki | 18.727273 |
| Perch | 25.735714 |
| Pike | 42.476471 |
| Roach | 20.645000 |
| Smelt | 11.257143 |
| Whitefish | 28.800000 |
{'Bream': 30.41764705882353,
'Parkki': 18.727272727272727,
'Perch': 25.735714285714288,
'Pike': 42.476470588235294,
'Roach': 20.645,
'Smelt': 11.257142857142856,
'Whitefish': 28.8}
| Species | Weight | Length1 | Length2 | Length3 | Height | Width | |
|---|---|---|---|---|---|---|---|
| 0 | Bream | 242.0 | 23.200000 | 25.4 | 30.0 | 11.5200 | 4.0200 |
| 1 | Bream | 290.0 | 24.000000 | 26.3 | 31.2 | 12.4800 | 4.3056 |
| 2 | Bream | 340.0 | 23.900000 | 26.5 | 31.1 | 12.3778 | 4.6961 |
| 3 | Bream | 363.0 | 26.300000 | 29.0 | 33.5 | 12.7300 | 4.4555 |
| 4 | Bream | 430.0 | 30.417647 | 29.0 | 34.0 | 12.4440 | 5.1340 |
| … | … | … | … | … | … | … | … |
| 154 | Smelt | 12.2 | 11.500000 | 12.2 | 13.4 | 2.0904 | 1.3936 |
| 155 | Smelt | 13.4 | 11.700000 | 12.4 | 13.5 | 2.4300 | 1.2690 |
| 156 | Smelt | 12.2 | 12.100000 | 13.0 | 13.8 | 2.2770 | 1.2558 |
| 157 | Smelt | 19.7 | 13.200000 | 14.3 | 15.2 | 2.8728 | 2.0672 |
| 158 | Smelt | 19.9 | 13.800000 | 15.0 | 16.2 | 2.9322 | 1.8792 |
159 rows × 7 columns